Logical service grouping
Group monitors into named services — payments API, checkout flow, authentication — so your team thinks in services, not individual URLs and ports.
A live inventory of every service your team runs: current owner, who's on call right now, upstream dependencies, links to dashboards and runbooks, and health at a glance — all in one place.
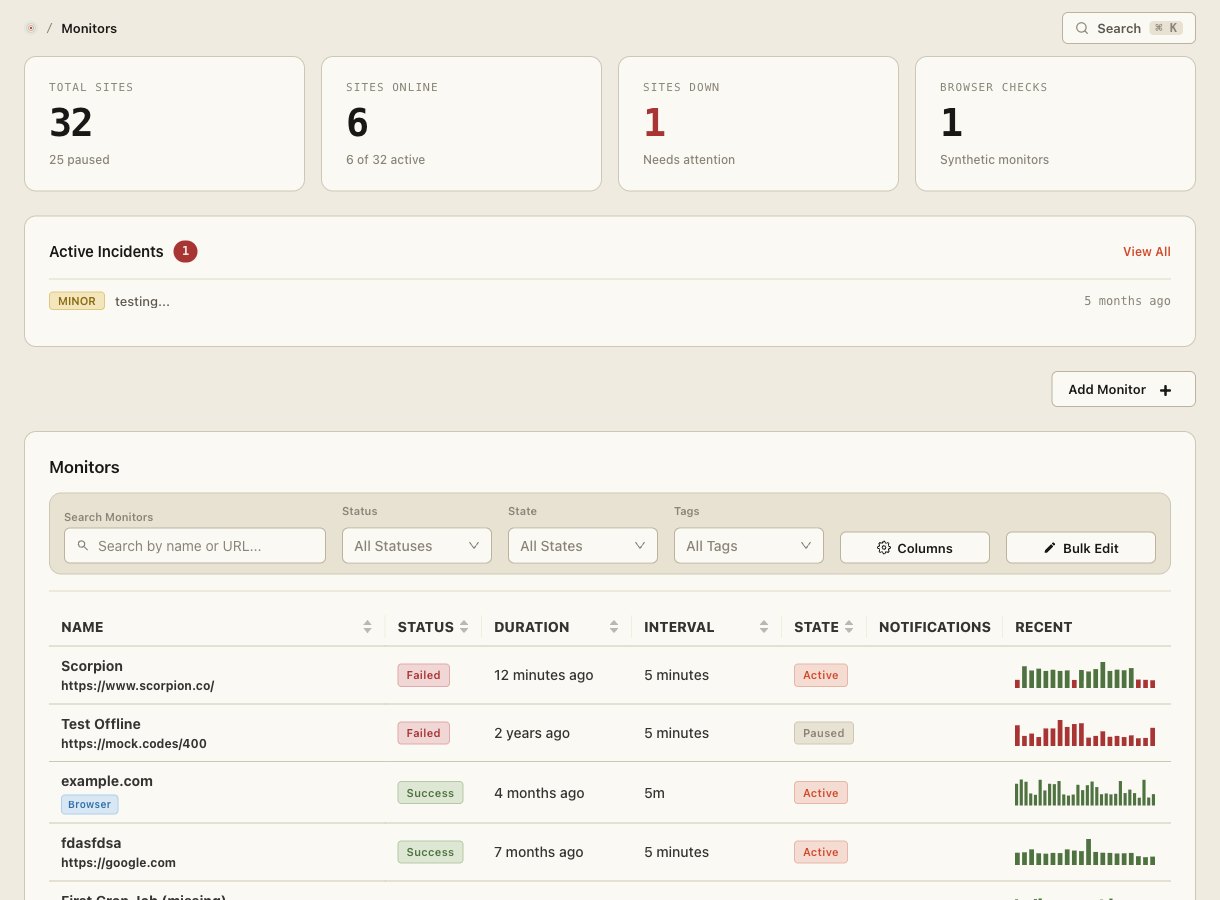
The service catalog is the authoritative answer to ownership, on-call coverage, dependencies, and current health for every service in your stack. It connects your monitors, incidents, escalation policies, and runbooks into a single operable view.
Group monitors into named services — payments API, checkout flow, authentication — so your team thinks in services, not individual URLs and ports.
Every service has an owner team and a linked on-call schedule. A single page tells you who's responsible and who to page right now — no chasing people in Slack.
Record upstream and downstream dependencies so responders immediately understand blast radius when a service degrades. No more incident archaeology to figure out what depends on what.
Attach links to runbooks, dashboards, code repositories, and wikis directly to a service. Everything a responder needs is one click away during a live incident.
Incidents created on a service automatically route through the service's escalation policy, with no manual assignment required. The right team is paged every time.
Tie a service to a component on your public status page. When an incident is created, the component status updates automatically, keeping your users informed without extra steps.
The catalog homepage shows current health for every service — green, degraded, or down — derived from live monitor data. During an incident it's the first screen your team opens to understand scope and impact before diving deeper.
Define services, owners, dependencies, and policy assignments via the REST API. Drop the calls into a script your repo owns, and changes go through your normal pull-request process — reviewed, approved, applied — so nobody updates the catalog by hand in a UI.
place for every service's owner, on-call, and health
manual steps to route an incident to the right team
dependency levels visible per service card
free tier — service catalog included from the start
A service is a named logical unit that groups one or more monitors, carries an owner, links to an escalation policy and on-call schedule, and optionally maps to a status page component. It's how your team thinks about your infrastructure, not how your infrastructure is physically arranged.
Health is derived from the monitors linked to the service. If any monitor is failing, the service shows as degraded or down. Open incident count and severity are shown alongside the monitor-derived health signal.
Yes. You can mark upstream and downstream dependencies for each service. During an incident, the service detail page shows you whether any of its dependencies are also degraded, which helps responders understand blast radius immediately.
Yes. Link a service to a component on your public status page. When an incident is declared on the service, the component status updates automatically, and when the incident resolves, the component returns to "Operational."
Yes — every catalog field (owner, escalation policy, on-call schedule, runbook URL, dependency links) is settable via the REST API. Drop the JSON definitions into your repo and your standard pull-request review applies them.
Uptime, cron, synthetic, logs, RUM, incidents, and status pages. Free tier on every product.